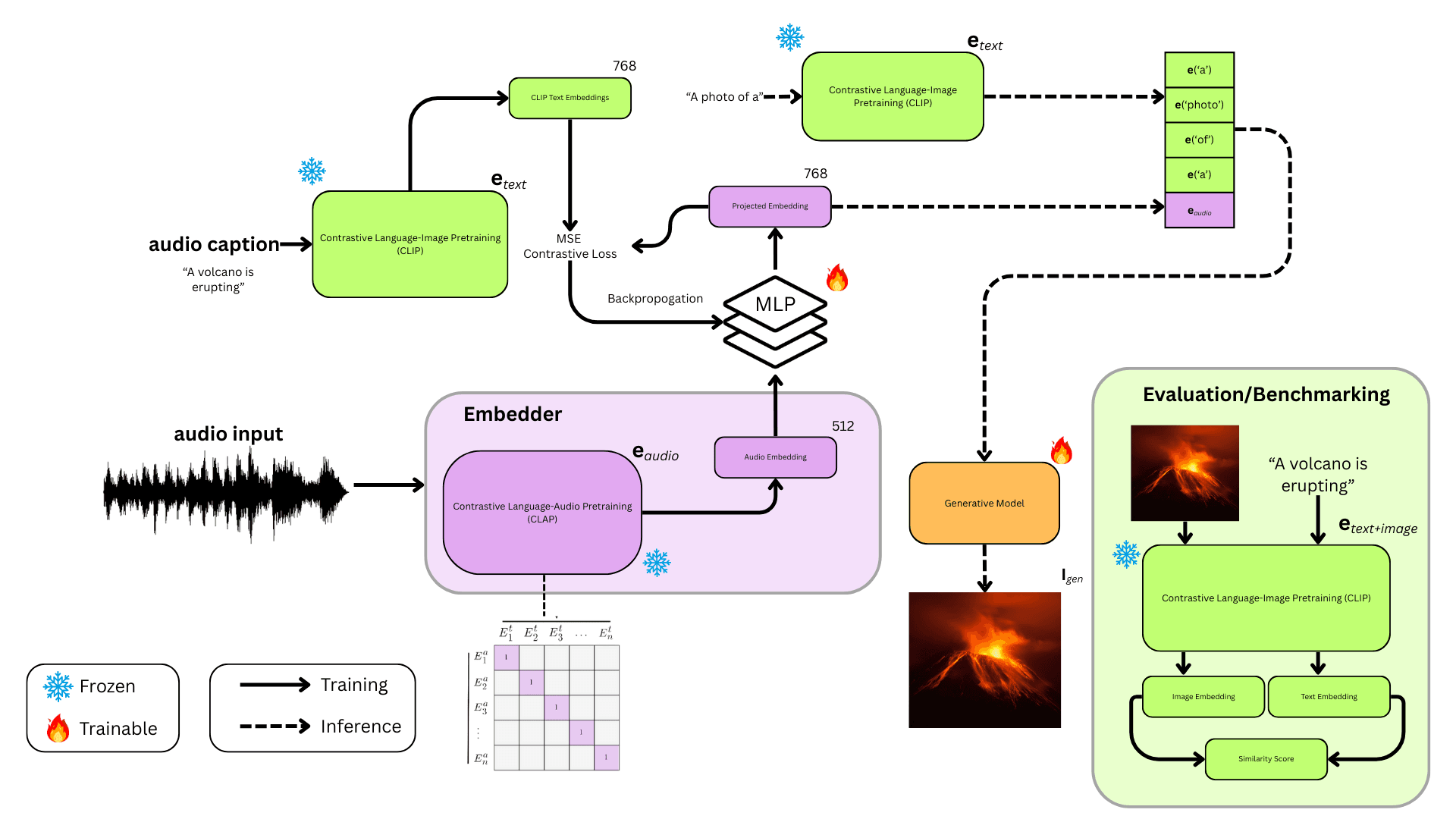
Developed a system that generates images from audio inputs by bridging Stable Diffusion with a custom-trained MLP adapter.
The Challenge
Standard image generation models take text as input. My team and I wanted to explore image generation using audio as an input instead.
The goal was to take an audio sample of bird's call and generate a realistic image of that specific species without any text prompts.
System Architecture
We developed a two-phase pipeline to bridge the gap between audio and visual modalities:
Phase 1: Audio Processing → MLP Adapter Train an MLP to learn how to convert an audio input to the input embedding that Stable Diffusion expects.
Phase 2: Stable Diffusion with LoRA Fine-tune Stable Diffusion with LoRA adapters to specialize the model for bird imagery.
Inference: Send an audio file of a bird to the MLP which generates the corresponding SD embedding. This embedding is then passed to the fine-tuned Stable Diffusion model to generate the image of the bird.
This architecture allows sound waves to directly control the image generation process without any text intermediary.
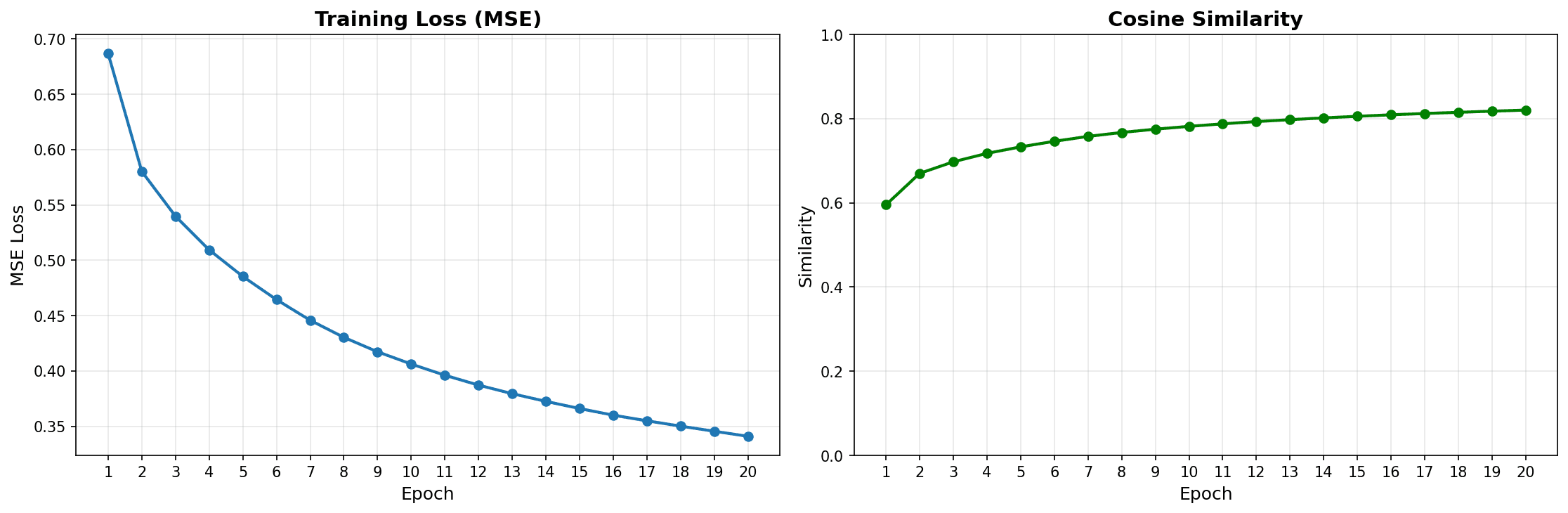
Training the MLP Adapter
The Multi-Layer Perceptron learns to translate audio features into the same mathematical language that Stable Diffusion understands which is the SD embeddings.
Over 20 epochs of training, the MLP achieved strong convergence: MSE loss dropped from 0.68 to 0.34, while Cosine Similarity between predicted and target embeddings reached 0.82. This high similarity score demonstrates that the adapter successfully learned the cross-modal mapping between acoustic signatures and visual concepts.
Fine-Tuning & Evaluation
To generate species-specific details, I fine-tuned Stable Diffusion using Low-Rank Adaptation (LoRA) on curated bird imagery from VGGSound. LoRA preserves the model's general capabilities while specializing it for ornithology.
The results validate the approach: comparing baseline Stable Diffusion to the MLP + LoRA pipeline showed a 67% increase in CLIP scores (15.43 → 25.82). Qualitatively, the baseline produces a generic brownish bird, while the fine-tuned model correctly generates a vibrant Baltimore Oriole with accurate orange/black plumage, all from just the audio of its chirping song.
